Ship safe GenAI apps without slowing down
ABV Guardrails stopprompt injectionshallucinationsdata leaksbefore they reach production.



Cost Effective
2x cheaper than building your own guardrails.

Fast
Sub-100ms latency for real-time LLM protection.
Trusted
Every guardrail is tested in-house and ships with re-evaluation tools.
Scalable
Built to scale from prototype to millions of requests.
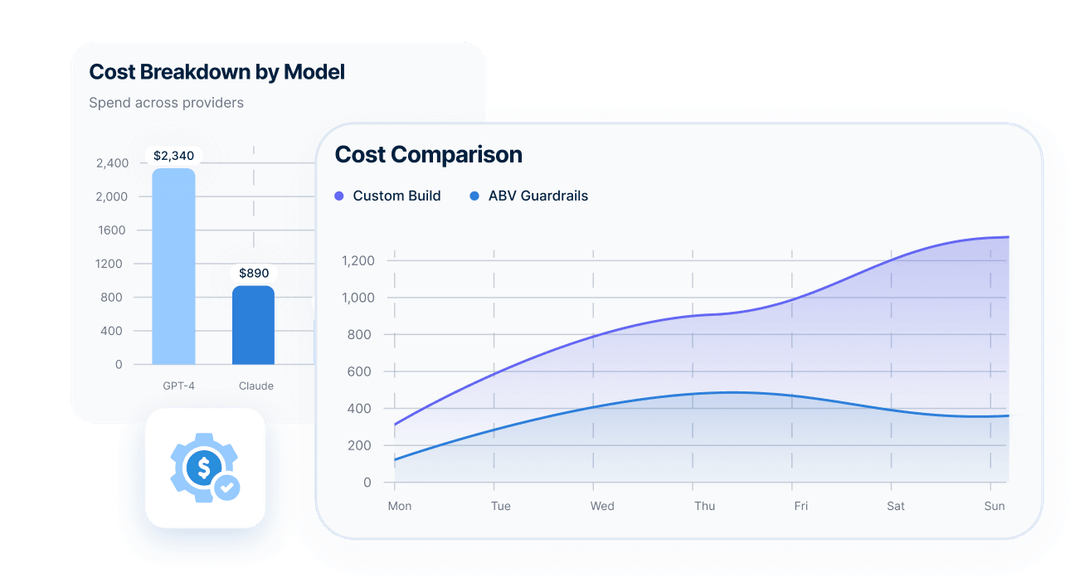
ABV Guardrails are Fast, Cost-Effective, and Accurate
Cheaper *


More Accurate *


Guardrails Response Time


*ABV guardrails are benchmarked against publicly available datasets.



Key LLM Metrics Scoring for Guardrails and Monitoring
With the ABV guardrails, you can score an extensive set of metrics, ensuring your LLM applications deliver the most advanced LLM use cases and stringent business demands. At the same time, it safeguards your LLM applications from harmful and costly risks.
Hallucination
- Answer relevance
- Factual consistency
- Source attribution
- Claim verification
- Numerical accuracy
- Temporal accuracy


Quality
- Conciseness
- Coherence
- Completeness
- Citation accuracy
- Knowledge cutoff awareness


Safety
- PII (SSN, credit cards, emails, phone numbers)
- Secrets detection (API keys, passwords, tokens)
- Jailbreak attempts
- Indirect prompt injection
- Code injection
- System prompt leakage


Compliance
- Topic restrictions
- Banned keywords/phrases
- Hate speech
- Bias detection (gender, race, age)
- Language detection
- Sentiment analysis
- Brand safety
- Regulatory compliance (GDPR, HIPAA, etc.)




Complete Protection for GenAI Apps
A powerful layer of security for your GenAI-enabled stack.
Ensure GenAI systems stay within their defined purpose even when facing manipulation attempts. Prevent unauthorized model behavior and stop bad actors while allowing legitimate use. Block prompt injection and jailbreak attempts in real-time without reducing performance.


Adapt to Evolving GenAI Risk
Traditional tools are blind to GenAI-specific threats.
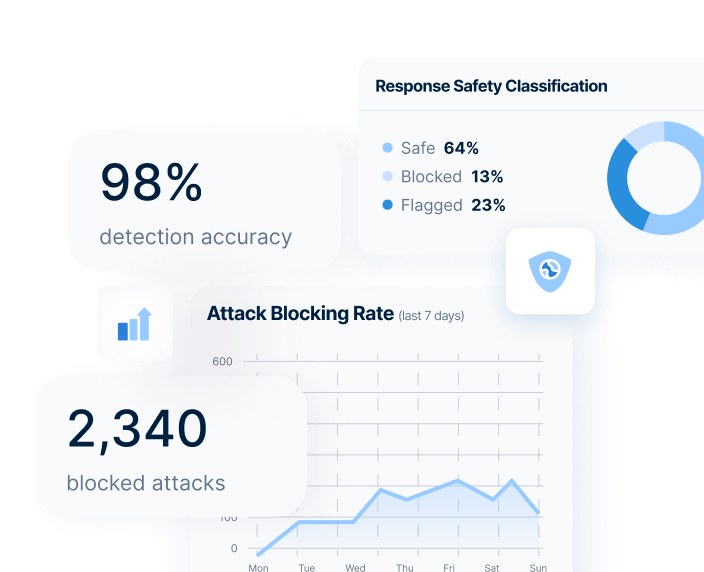
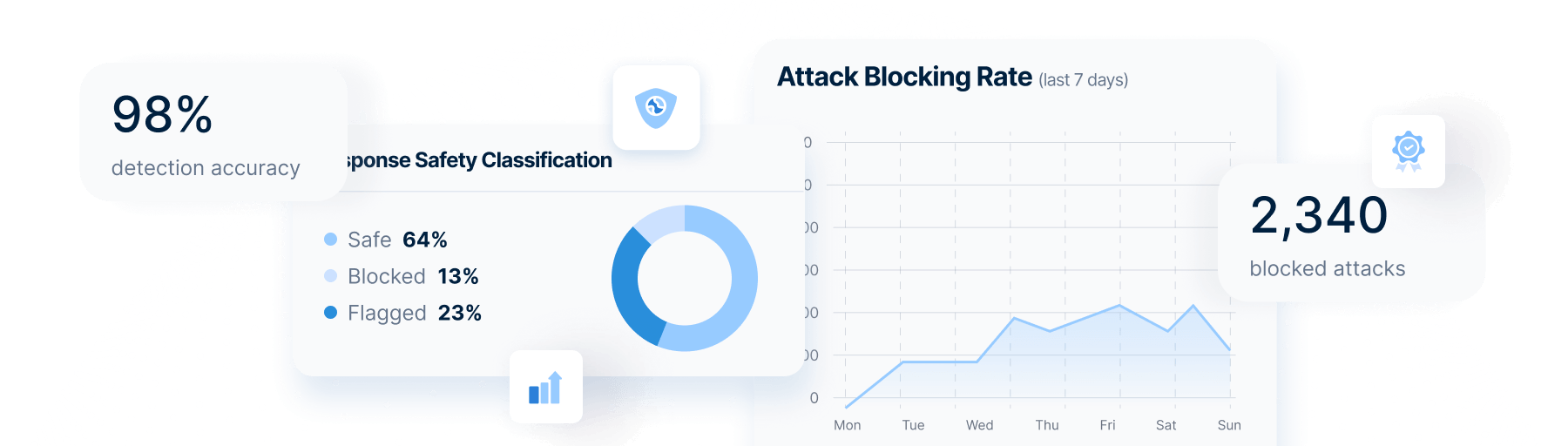
72% of organizations report jailbreak attempts on production AI applications. ABV detects and blocks these attacks in real-time, ensuring only validated responses reach your users — even when models are actively manipulated.
Minimize Risk
Minimize risk with real-time threat detection at the network level.
Lower Costs
Lower costs by automating and scaling AI governance.
Protection
Protect your reputation by preventing offensive or confusing interactions.
Questions & Answers
LLM guardrails are real-time validation systems that check AI-generated content before it reaches users or production systems. They detect and block harmful outputs like hallucinations, prompt injections, toxic language, PII leaks, and off-topic responses. Guardrails run in milliseconds, ensuring your AI applications stay safe without sacrificing user experience.
Even leading LLMs like GPT-4, Claude, and Gemini produce hallucinations, can be manipulated through prompt injection, and occasionally generate inappropriate content. Foundation models have broad safety filters, but they don't understand your specific business rules, compliance requirements, or brand guidelines. Guardrails provide an additional validation layer tailored to your use case—catching issues that slip through the model's built-in protections.
ABV guardrails respond in under 300ms—fast enough for real-time user-facing applications. Rule-based guardrails (pattern matching, schema validation) run in under 10ms. LLM-powered guardrails (semantic analysis for toxicity, bias, hallucination detection) typically take 1-3 seconds. You can chain multiple guardrails and still maintain sub-second response times for most workflows.
Yes. You can configure existing guardrails with custom thresholds, banned keyword lists, allowed topics, or compliance rules specific to your industry (HIPAA, GDPR, financial regulations). You can also build custom guardrails using your own validation logic or domain-specific LLM prompts. For example, financial services might add guardrails that block investment advice disclaimers, while healthcare apps might enforce HIPAA-compliant PHI masking.
ABV's hallucination detection guardrails achieve 30% higher accuracy than publicly available alternatives by using specialized prompt engineering and multi-model verification. However, no guardrail is perfect—hallucination detection is probabilistic, not deterministic. Best practice is to combine multiple guardrails (faithfulness checks, source grounding, factual consistency) and set confidence thresholds based on your risk tolerance.
You decide. Common patterns:
- Block: Reject the output and return a generic error to the user
- Regenerate: Retry the LLM call with modified instructions or different parameters
- Flag for review: Allow the output through but log it for human review
- Modify: Automatically redact or mask problematic content (e.g., PII masking)
- Escalate: Route to a human agent or fallback system
You can configure different actions for different guardrails based on severity.
Cost various, but for most applications, ABV guardrail costs are 2x cheaper than building equivalent validation logic yourself, and they scale to millions of requests without custom infrastructure.
Yes, and you should. Production applications typically chain 3-7 guardrails together:
Pre-generation (input validation):
- Prompt injection detection
- Malicious input filtering
- Topic enforcement
Post-generation (output validation):
- Hallucination detection
- Toxicity filtering
- PII masking
- Brand safety checks
Guardrails run in sequence or parallel depending on dependencies, with total latency typically under 500ms for the full chain.
